事務部門の業務に応用できる基本的な15種類のAI活用事例
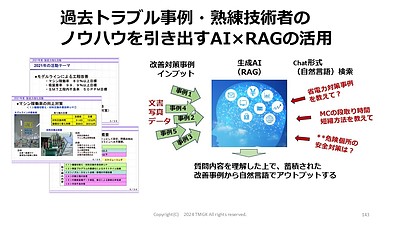
RAG(Retrieval-Augmented Generation:検索拡張生成)とは、
一言でいえば「AIに、自社専用の『カンニングペーパー(社内資料などの
外部知識)』を読ませてから答えさせる仕組み」のことです。
AI(LLM)が回答を生成する前に、社内文書や過去のデータから関連情報
を検索し、その情報を基に回答させます。
一般的な生成AI(ChatGPTなど)は、事前に学習した時点でのデータしか
持っていないため、「最新情報に疎い」「社内限定の独自のルールやマニュ
アルを知らない」「知らないことでももっともらしい嘘をつく(ハルシネー
ション)」といった弱点があります。
RAGは、これらの弱点を克服し、実務で使える精度の高いAIを構築するため
の技術です。
具体的には、以下の3つのステップで機能します。
①検索(Retrieval)
ユーザーの質問に関連する情報を、社内のマニュアルや過去のトラブル
データベースから探し出します。
②拡張(Augmentation)
見つけ出した自社の情報を、ユーザーの質問と一緒にAIにセットし、「この
資料を読んで答えて」と指示を加えます。
③生成(Generation)
渡された資料のみを根拠にして、AIが正確な回答を作成します。
RAGを活用することで、企業には以下のような大きなメリットがあります。
①回答の信頼性向上(ハルシネーションの防止)
自社の資料という明確な根拠に基づいて回答するため、現場で使い物に
ならない一般論や、AI特有の「嘘」を大幅に減らすことができます。
②常に最新の情報を保てる(再学習が不要)
AIのモデル自体に時間とコストをかけて再学習(ファインチューニング)
させる必要がありません。外部の参照データを追加・更新するだけで、
常に最新の情報をAIに提供できます。
③強固なセキュリティの確保
社外秘の設計図やトラブル報告書といった機密情報を、外部に漏らす
ことなく社内環境だけでAIに参照させることができます。
「濱田式AI品質スタンダード」では、Googleの「NotebookLM」などの
ツールを用いてこのRAG環境を構築します。
これまでファイルサーバーの奥底で眠っていた過去の不具合報告書や、熟練
者の頭の中にしかなかった「勘やコツ」を、誰もが自然言語で瞬時に引き出
せる「生きたデジタル資産」へと変換し、新人向けのトレーニングボットや
設計段階でのトラブル未然防止に役立てています。